Reddit offers a fairly extensive API that any developer can use to easily pull data from subreddits. You can fetch posts, user comments, image thumbnails, votes and most other attributes that are attached to a post on Reddit.
The only downside with the Reddit API is that it will not provide any historical data and your requests are capped to the 1000 most recent posts published on a subreddit. So, for instance, if your project requires you to scrape all mentions of your brand ever made on Reddit, the official API will be of little help.
You have tools like wget that can quickly download entire websites for offline use but they are mostly useless for scraping Reddit data since the site doesn’t use page numbers and content of pages is constantly changing. A post can be listed on the first page of a subreddit but it could be pushed to the third page the next second as other posts are voted to the top.
Download Reddit Data with Google Scripts
While there exist quite a Node.js and Python libraries for scraping Reddit, they are too complicated to implement for the non-techie crowd. Fortunately, there’s always Google Apps Script to the rescue.
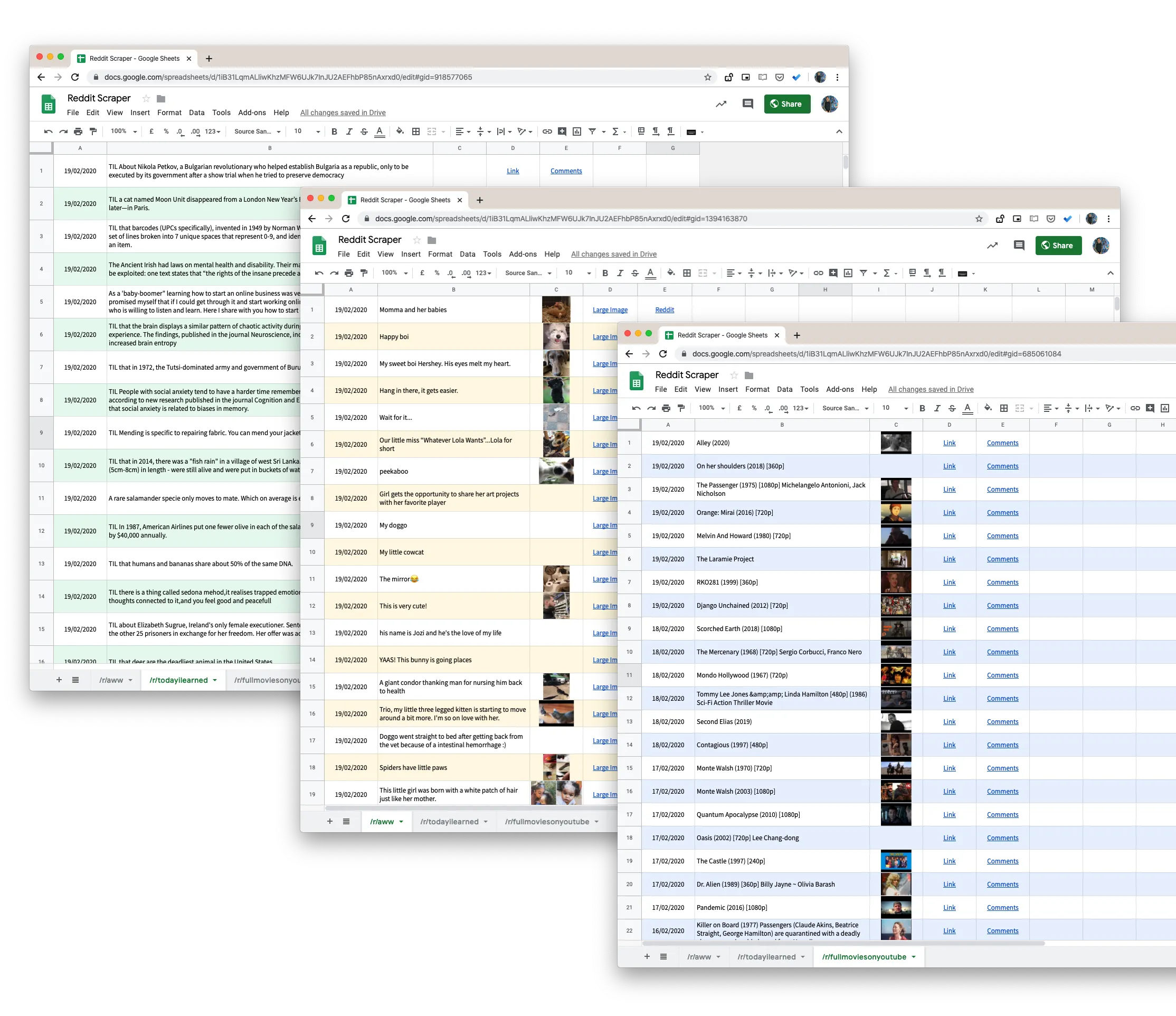
Here’s Google script that will help you download all the user posts from any subreddit on Reddit to a Google Sheet. And because we are using pushshift.io instead of the official Reddit API, we are no longer capped to the first 1000 posts. It will download everything that’s every posted on a subreddit.
- To get started, open the Google Sheet and make a copy in your Google Drive.
- Go to Tools -> Script editor to open the Google Script that will fetch all the data from the specified subreddit. Go to line 55 and change
technologyto the name of the subreddit that you wish to scrape. - While you are in the script editor, choose
Run -> scrapeReddit.
Authorize the script and within a minute or two, all the Reddit posts will be added to your Google Sheet.
Technical Details - How to the Script Works
The first step is to ensure that the script not hitting any rate limits of the PushShift service.
const isRateLimited = () => {
const response = UrlFetchApp.fetch('https://api.pushshift.io/meta');
const { server_ratelimit_per_minute: limit } = JSON.parse(response);
return limit < 1;
};Next, we specify the subreddit name and run our script to fetch posts in batches of 1000 each. Once a batch is complete, we write the data to a Google Sheet.
const getAPIEndpoint_ = (subreddit, before = '') => {
const fields = ['title', 'created_utc', 'url', 'thumbnail', 'full_link'];
const size = 1000;
const base = 'https://api.pushshift.io/reddit/search/submission';
const params = { subreddit, size, fields: fields.join(',') };
if (before) params.before = before;
const query = Object.keys(params)
.map((key) => `${key}=${params[key]}`)
.join('&');
return `${base}?${query}`;
};
const scrapeReddit = (subreddit = 'technology') => {
let before = '';
do {
const apiUrl = getAPIEndpoint_(subreddit, before);
const response = UrlFetchApp.fetch(apiUrl);
const { data } = JSON.parse(response);
const { length } = data;
before = length > 0 ? String(data[length - 1].created_utc) : '';
if (length > 0) {
writeDataToSheets_(data);
}
} while (before !== '' && !isRateLimited());
};The default response from Push Shift service contains a lot of fields, we are thus using the fields parameter to only request the relevant data like post title, post link, date created and so on.
If the response contains a thumbnail image, we convert that into a Google Sheets function so you can preview the image inside the sheet itself. The same is done for URLs.
const getThumbnailLink_ = (url) => {
if (!/^http/.test(url)) return '';
return `=IMAGE("${url}")`;
};
const getHyperlink_ = (url, text) => {
if (!/^http/.test(url)) return '';
return `=HYPERLINK("${url}", "${text}")`;
};Bonus Tip: Every search page and subreddit on Reddit can be converted into JSON format using a simple URL hack. Just append .json to the Reddit URL and you have a JSON response.
For instance, if the URL is https://www.reddit.com/r/todayIlearned, the same page can be accessed in JSON format using the URL https://www.reddit.com/r/todayIlearned.json.
This works for search results as well. The search page for https://www.reddit.com/search/?q=india can be downloaded as JSON using https://www.reddit.com/search.json?q=india.





