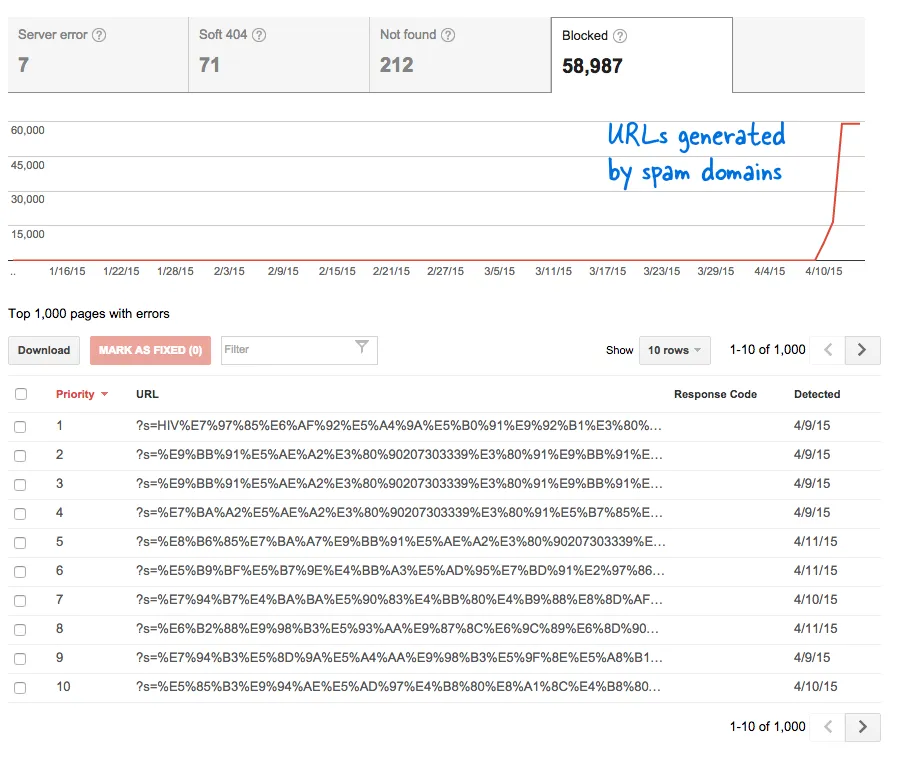
If you are using Google Custom Search or another site search service on your website, make sure that the search results pages - like the one available here - are not accessible to Googlebot. This is necessary else spam domains can create serious problems for your website for no fault of yours.
Few days ago, I got an automatically generated email from Google Webmaster Tools saying that Googlebot is having trouble indexing my website labnol.org as it found a large number of new URLs. The message said:
Googlebot encountered extremely large numbers of links on your site. This may indicate a problem with your site’s URL structure… As a result Googlebot may consume much more bandwidth than necessary, or may be unable to completely index all of the content on your site.
This was a worrying signal because it meant that tons of new pages have been added to the website without my knowledge. I logged into Webmaster Tools and, as expected, there were thousands of pages that were in the crawling queue of Google.
Here’s what happened.
Some spam domains had suddenly started linking to the search page of my website using search queries in Chinese language that obviously returned no search results. Each search link is technically considered a separate web page - as they they have unique addresses - and hence the Googlebot was trying to crawl them all thinking they are different pages.
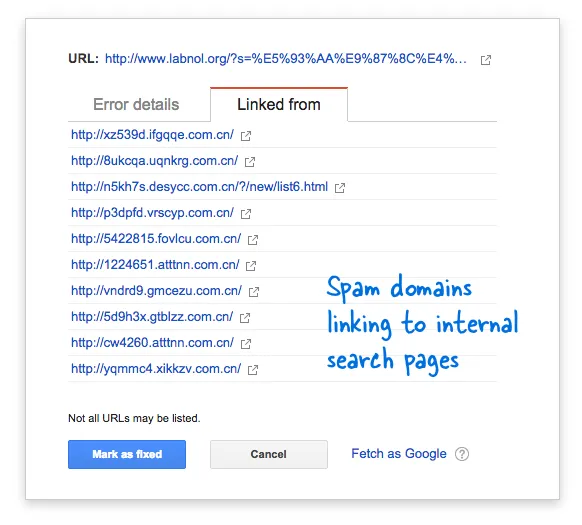
Because thousands of such fake links were generated in a short span of time, Googlebot assumed that these many pages have been suddenly added to the site and hence a warning message was flagged.
There are two solutions to the problem.
I can either get Google to not crawl links found on spam domains, something which is obviously not possible, or I can prevent the Googlebot from indexing these non-existent search pages on my website. The latter is possible so I fired up my VIM editor, opened the robots.txt file and added this line at the top. You’ll find this file in the root folder of your website.
User-agent: *
Disallow: /?s=*Block Search pages from Google with robots.txt
The directive essentially prevents Googlebot, and any other search engine bot, from indexing links that have the “s” parameter the URL query string. If your site uses “q” or “search” or something else for the search variable, you may have to replace “s” with that variable.
The other option is to add the NOINDEX meta tag but that won’t have been an effective solution as Google would still have to crawl the page before deciding not to index it. Also, this is a WordPress specific issue because the Blogger robots.txt already blocks search engines from crawling the results pages.
Related: CSS for Google Custom Search