File a DMCA Complaint with the help of Google Docs
The moment you publish a new article on your website or blog, the “web scraping” bots around the world will spring into action. They’ll copy your articles to publish them on other websites and the fact that you syndicate content through RSS feeds makes their “copy-paste” job even simpler.
These bots are often lazy – they would rarely modify your articles before republishing them – and thus it becomes very easy for you as well to identify the sites that are using your content without permission. For instance, I add a line “This story was originally published at Digital Inspiration” to the feed and thus a quick Google search can reveal the names of sites that are possibly copying my stories.
The easiest way to deal with online plagiarism is that you send a DMCA notice to search engines, the web hosting provider and the advertising partners (like AdSense) of the offending site. Google Search requires you to fax the DMCA notices, AdSense offers an online form while most web hosts accept DMCA over e-mail.
Find Copies of your Work with Google Docs
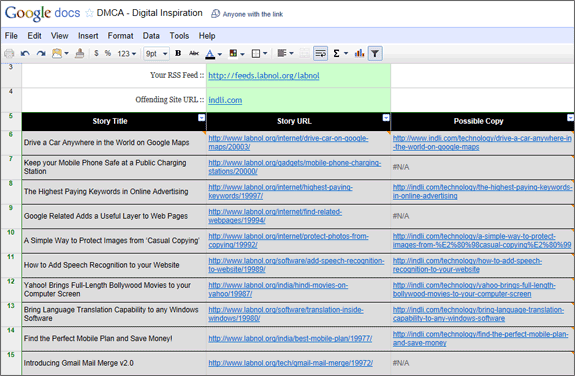
It is pretty easy to write a DMCA complaint but there’s one section in the form that may involve a little effort – you need to provide a list of URLs of pages that “allegedly contain infringing material” and also the corresponding URLs that contain the original work.
If you have been looking for a tool that can automatically generate this list for you, take a peek at this Google Docs Sheet. Make sure you are signed in with your Google Account and the use File -> Make a copy to create your own working copy of the Google Sheet. Then put in your site’s RSS feed URL in the Cell B3 and the URL of offending site in Cell B4 and the sheet will create the data you need for the DMCA.
What happens behind the scenes
Here’s how the above Google Docs sheet work - it take your RSS feed and determines the title and the URL of your 10 recently published stories using the ImportFeed function.
The sheet then runs a separate Google Search for each of the 10 stories to determine if a story with the same title exists on the offending site. If a copy is found, the URL of that page is extracted from Google Search using XPath and ImportXML as shown below.
\=ImportXML(CONCATENATE(”http://www.google.com/search?q=intitle:%22”, A6, “%22 site:”, $B$4), “//a[@class=‘l’]/@href”)
If you are getting an N/A for some fields, it either indicates that the particular story was not found on the offending site or it could be temporary problem with Google search as well.

Amit Agarwal
Google Developer Expert, Google Cloud Champion
Amit Agarwal is a Google Developer Expert in Google Workspace and Google Apps Script. He holds an engineering degree in Computer Science (I.I.T.) and is the first professional blogger in India.
Amit has developed several popular Google add-ons including Mail Merge for Gmail and Document Studio. Read more on Lifehacker and YourStory